Implementing a paper: Controlling DDoS attack traffic using reinforcement learning
0. Related Links
- Reference Paper:
DDoS Traffic Control Using Transfer Learning DQN With Structure Information | IEEE Journals & Magazine | IEEE Xplore - Project GitHub Link: ryujm1828/DDoS_Traffic_Control_RL
- Explanatory YouTube Link: (To be added)
1. Introduction
As someone who has been studying both security and AI, I wanted to undertake a meaningful project that merges these two fields. Initially, I considered projects like using AI to identify phishing emails or malware. However, I concluded that the limited availability of datasets and the difficulty of acquiring my own would make it challenging to add significant depth to such a project.
Then, I came across a research paper suggesting that Reinforcement Learning (RL) could be used to control DDoS attack traffic. This was particularly exciting because RL is the area of AI I have studied most deeply. Furthermore, the ability to train a model through a simulation environment without needing a massive, pre-existing dataset was a huge advantage.
I decided to implement the basic idea from this paper and then build upon it by adding my own original concepts.
💡 Note: This post is not a detailed review of the paper itself, but a record of the project I built and expanded upon by referencing it.
2. A Brief Overview of the Reference Paper
Let's start by looking at the server architecture defined in the paper.
Server Structure
The architecture is divided into a [Server - Team Leader Router - Intermediate Router - Throttling Router] hierarchy. It's not a fully connected mesh but a tree-like structure. The throttling routers are at the bottom layer, interfacing with the external network. Our goal is to control the amount of traffic these routers throttle.
The core ideas of the reference paper are as follows:
It presumes an internet environment with terminals (representing attackers and legitimate users) and a multi-layer router structure connecting these terminals to a server. Each router acts as an agent, deciding its own throttling rate—the act of intentionally dropping traffic—based on the current state.
-
State: The information observed by the agent (router). The paper proposes three main models:
- DCTL (Base Model): The state only includes the amount of traffic currently being received by the routers within its own team.
- DCTL-TS (Adds Structural Information): Adds network topology information (the number of routers in each layer) to the DCTL state.
- PT DCTL-TS (Applies Transfer Learning): A method where a model trained with a small number of router teams is gradually adapted to more complex environments (with more teams).
-
Reward: The feedback for an agent's action.
- Does the team leader router traffic exceed the team's traffic quota (US/number of teams)?
- And does the total server traffic exceed the server's capacity limit (US)?
→ If both conditions 1 and 2 are met, -1. - Otherwise, reward = passed normal traffic/total normal traffic.
One limitation I noted was that in the paper's simulation, the attacker sends traffic at a constant and fixed intensity until the end of an episode. This made me wonder if an RL model could still perform effectively in an environment that more closely mimics real-world cyber conditions.
3. Project Introduction
I defined my project's direction by adding a layer of realism to the paper's base model. The key was to diversify the behavior patterns of the 'terminals'.
Newly Defined Terminal Types
- Normal User: A user who typically generates low traffic but can occasionally demand high traffic for short bursts, like when uploading an image.
- Streaming User: A user who generates a steady and consistent stream of traffic that is higher than a normal user's.
- Attacker: A terminal that consistently sends a very high volume of traffic at every step.
Simulation Environment Design
- Intermittent Attacks: I believed that training only on relentless, non-stop attacks would degrade the model's ability to handle peaceful, normal conditions. Therefore, I implemented a system where attacks occur with a certain probability for a specific duration during the simulation.
- Realistic Server Capacity: I set the server capacity based on the average number of users during normal conditions, plus a small buffer (delta). I felt this was crucial for effectively training a strategy to handle unexpected attack traffic on a server that is otherwise stable. This was set as the total number of terminals + delta, as in the paper, but I increased the delta value slightly to maintain stability during peacetime.
4. Project Results
All experiments were fundamentally based on the paper's DCTL-TS model. For each experiment, I focused on observing how the agents (routers) adjusted their throttling rates in response to an attack.
🔎 Key Observation Point: The RL agent determines its action at step A based on the state resulting from traffic processed at step A-1. Therefore, the critical point of observation is not the exact moment an attack occurs, but how the AI reacts in the steps immediately following the attack.
4-1. Single Router Concentrated Attack
I simulated a scenario where attack traffic was focused on a single router. (Average of 2.5 attacks per episode).
※ Graph Legend
- Pink Line: Reward at each step
- Blue Line: Average throttling rate of all throttling routers
- Red Dot: The moment of attack
- X-axis: Step


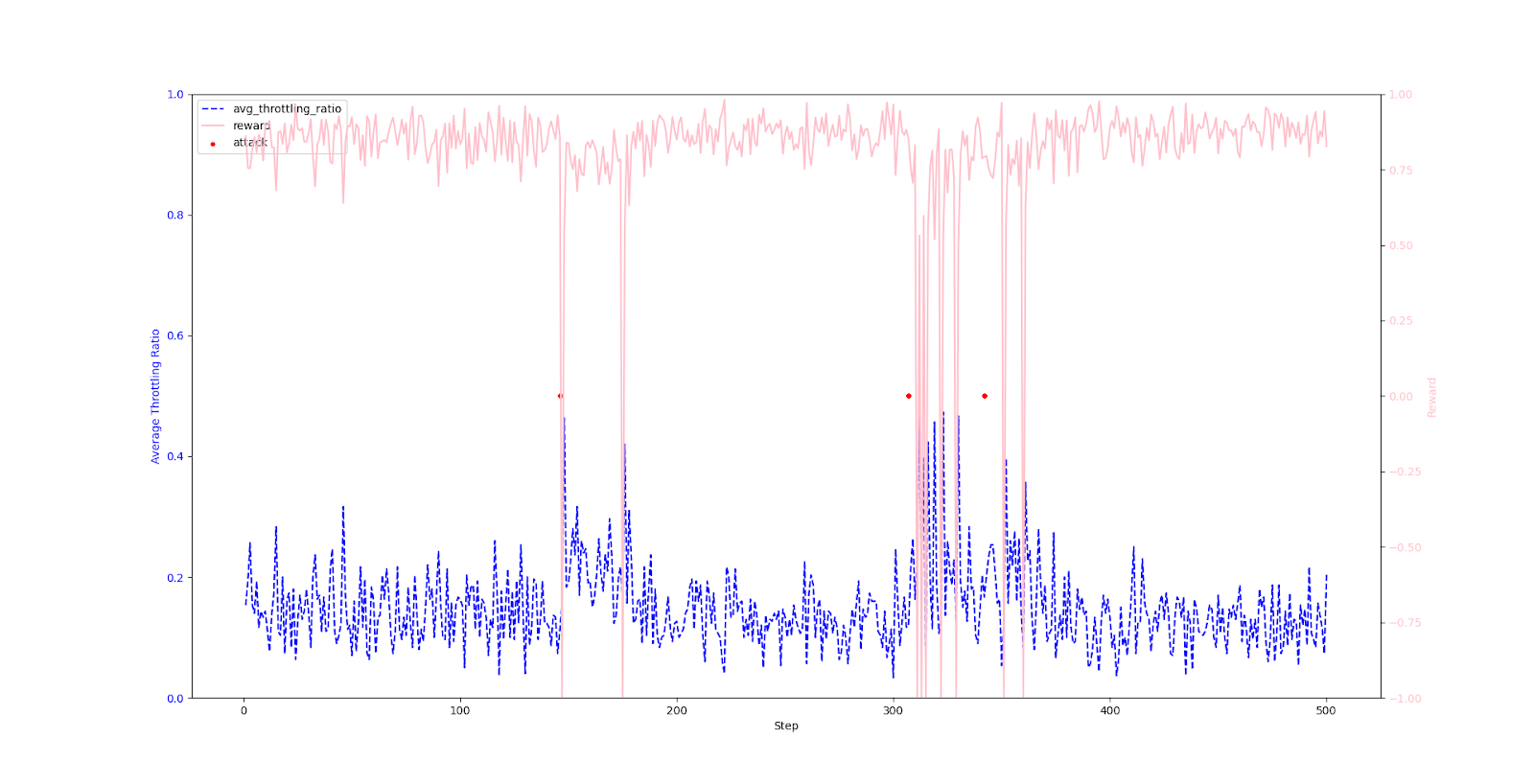
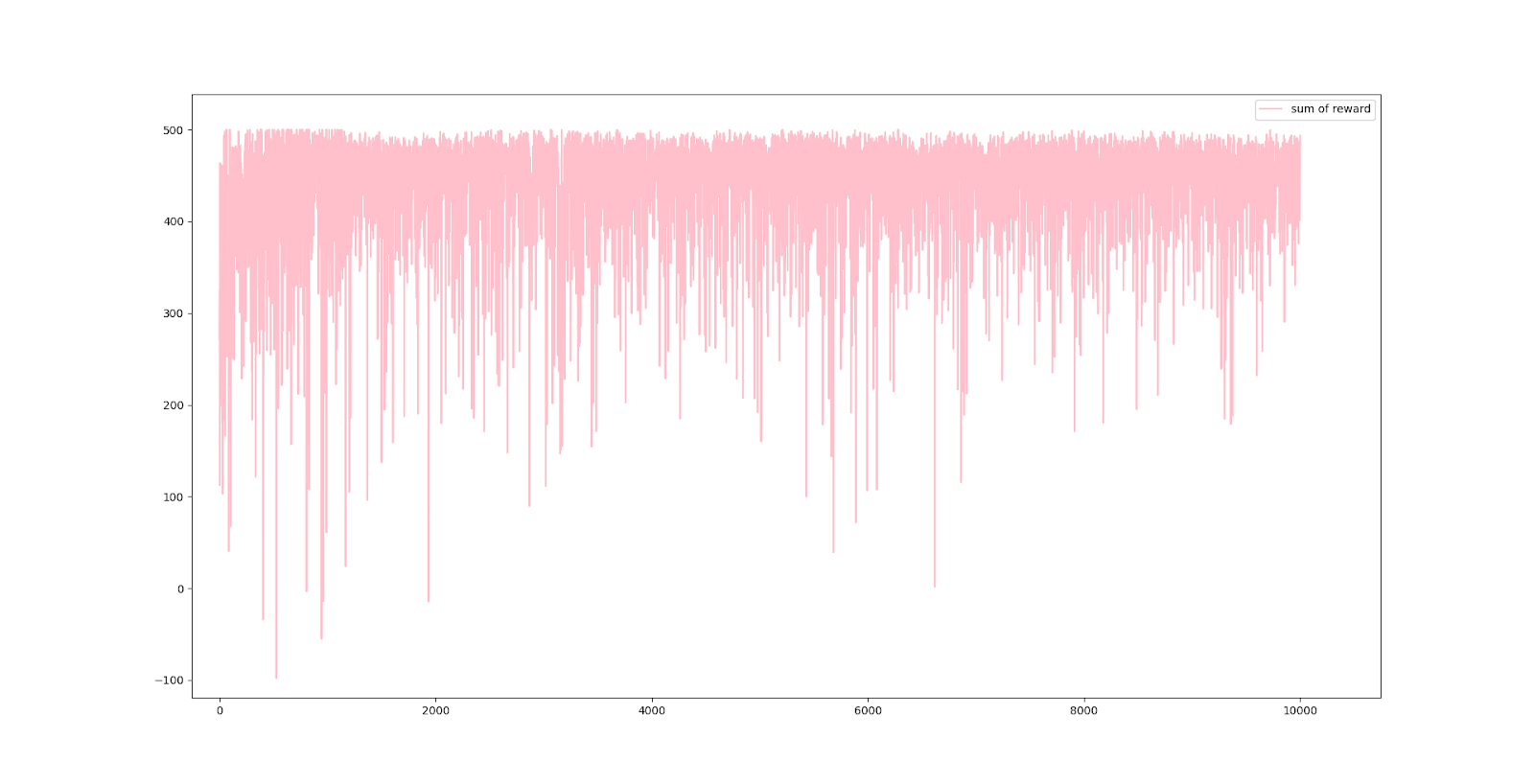
Single Router - Total Reward per Episode You can see the average reward trending upwards as training progresses. The high variance in the reward graph is due to the random intensity and frequency of attacks in each episode. This is a natural phenomenon where episodes with many severe attacks have lower rewards, and those with fewer attacks have higher rewards.
4-2. Multi-Router Attack
Next, I set up a more challenging scenario where multiple routers were attacked simultaneously. I slightly lowered the attack frequency compared to the previous experiment. This was because a very high attack frequency tended to teach the agent a passive strategy of "just keep all router throttling rates at a medium level."

Multi-Router - Before Training Similar to the single-router experiment, the throttling rate is erratic and the reward is low before training.
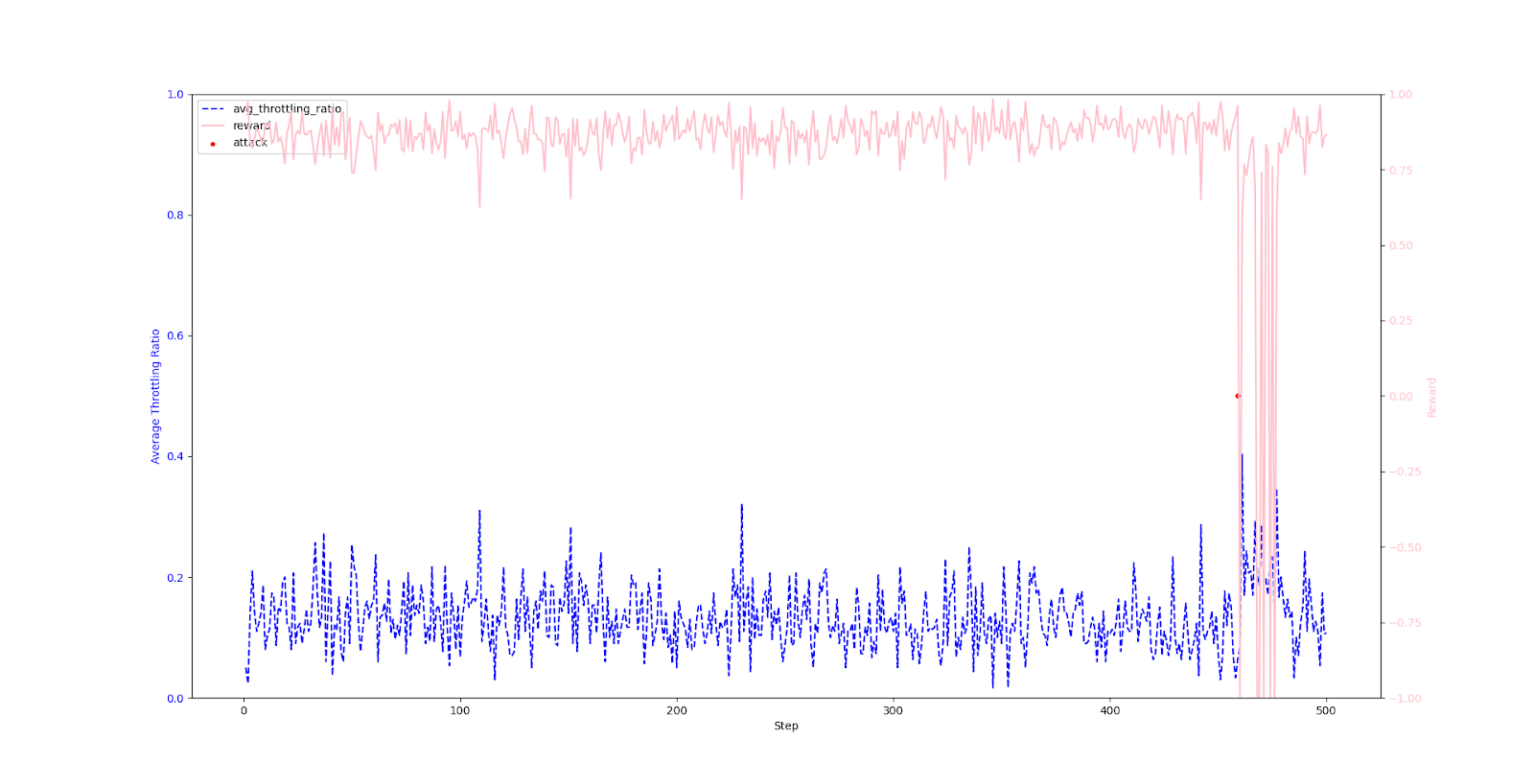
Multi-Router - After Training After 5,000 episodes, the agent successfully learned an efficient strategy: it defends by sharply increasing the throttling rate when an attack occurs, while maintaining a low rate during peacetime.
4-3. Dynamic Structure Environment + Multi-Router Attack
Finally, I simulated a multi-router attack in an environment where the router hierarchy's structure changes dynamically. Since the server's total traffic capacity is proportional to the number of routers, a structure with more routers is more robust against attacks, while one with fewer is more vulnerable.

Multi-Structure - After Training (Strong 6-6-6-6 Structure) In this strong structure with many routers (6-6-6-6), which is inherently advantageous for defense, the agent learned that it didn't need to throttle aggressively because the server remained stable. Consequently, it maintained a very low throttling rate regardless of attacks.
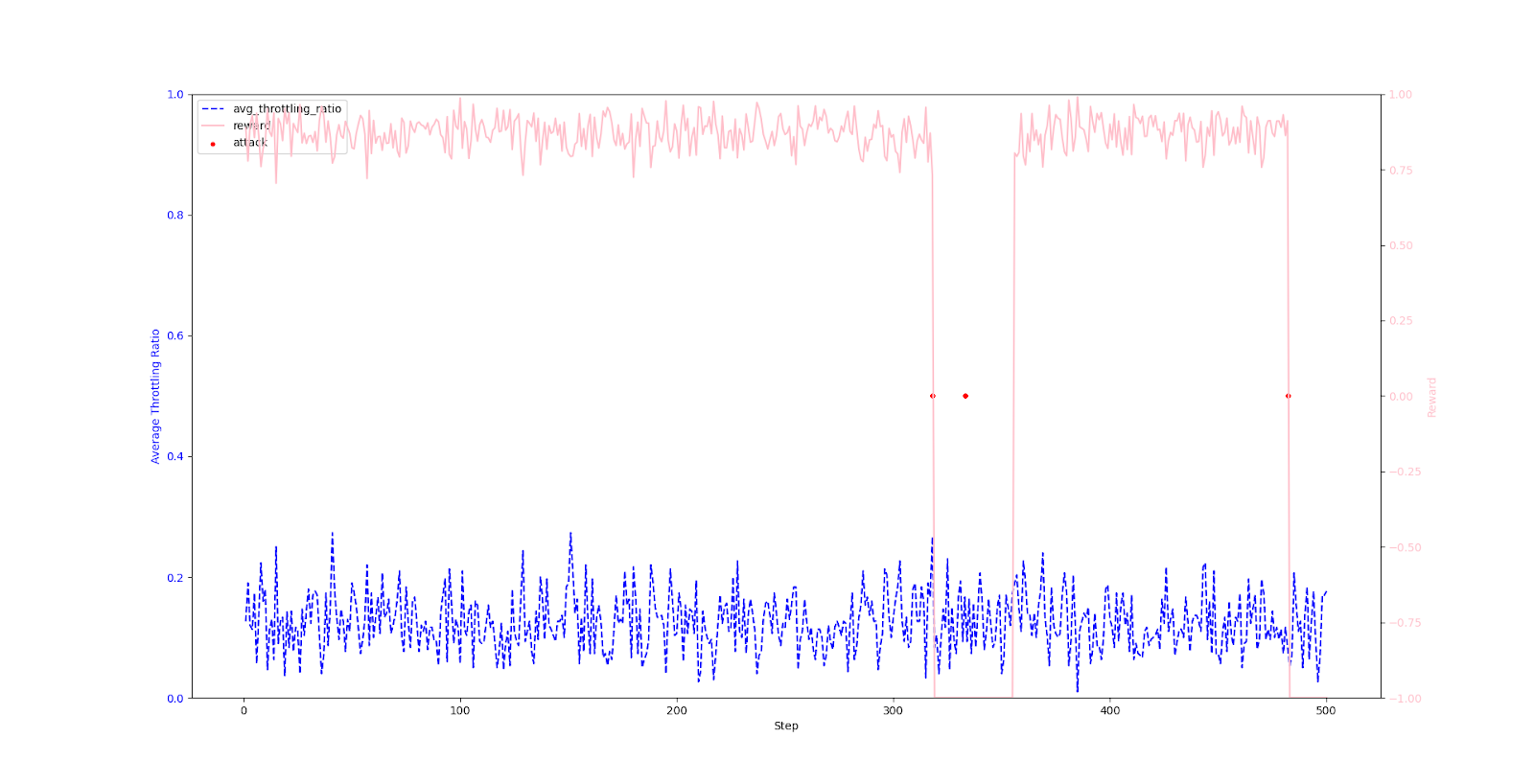
Multi-Structure - After Training (Moderate 5-2-3-3 Structure) This experiment, using a moderate structure identical to previous tests, yielded the most disappointing results. The agent failed to learn an effective strategy to counter attacks. I suspect the cause of failure was that it was trained alongside very robust structures (like 6-6-6-6) and the overall attack frequency was set too low.
5. Summary and Conclusion
This project aimed to implement the idea from a research paper on using RL to defend against DDoS attacks and to validate the model's effectiveness by applying more realistic scenarios.
Key Achievements
- Implemented an Autonomous RL-based DDoS Defense System: Successfully built a model where RL agents (routers) autonomously assess situations and control traffic, moving beyond static rule-based systems.
- Verified Defense Capabilities in a Dynamic Attack Environment: Confirmed that the RL model can learn effective defense strategies even in a more realistic environment with irregular, intermittent attacks and diverse user patterns, a step beyond the paper's fixed attack model. It demonstrated the ability to detect attacks and increase throttling to protect the server in both single and multi-router attack scenarios.
- Observed Adaptability to Network Structure Changes: Showed signs of learning environment-specific strategies, such as minimizing throttling in robust environments and responding more directly to attacks.
Limitations and Disappointments
The biggest disappointment was the failure to train effectively in an environment with mixed network structures. It seems that because training data included both advantageous and disadvantageous structures, combined with a low attack frequency, the agent lacked the motivation to learn an "aggressive response" pattern.
Future Work
To overcome the limitations of this project and improve upon it, the following directions could be considered:
- Apply Transfer Learning: As suggested in the paper, transfer learning could be applied to improve training efficiency and effectiveness across different structures.
- Incorporate Diverse Attack Scenarios: Beyond simple traffic floods, the simulation could be enhanced with more sophisticated attacks like Slow-Rate DDoS (SR-DDoS) or attacks with irregular traffic spike intervals.
In conclusion, this project demonstrates that Reinforcement Learning has significant potential as an intelligent and autonomous defense system against DDoS attacks in complex and dynamic network environments. I am hopeful that with more sophisticated models and training strategies, this approach can be developed to a level applicable in real-world networks.
댓글
댓글 쓰기